
我有一台 64GB RAM 的地端 AI 主機,平常系統總用量很少超過 16GB。那天睡眠喚醒後,瞄到用量靠近 32GB,直覺就覺得不對。打開工作管理員,最顯眼的那行是 llama-server.exe,排在所有程式最上面,佔了 17GB。
第一個念頭:GPU offload 掛了,Qwen3.6 27B 整個跑回 CPU 了?
但 nvidia-smi 一查,GPU1 8153MB、GPU2 8701MB,紋絲不動。推論速度 18.6 tok/s,也沒事。
那個 17GB 到底是什麼?
我沒有重開機。我寫了一個監控程式,把整個過程錄下來。
實測數據:163 筆,每 2 秒一筆
程式從喚醒前就跑著,Sleep/Resume 全程自動記錄。以下是這次事件的完整時間軸。
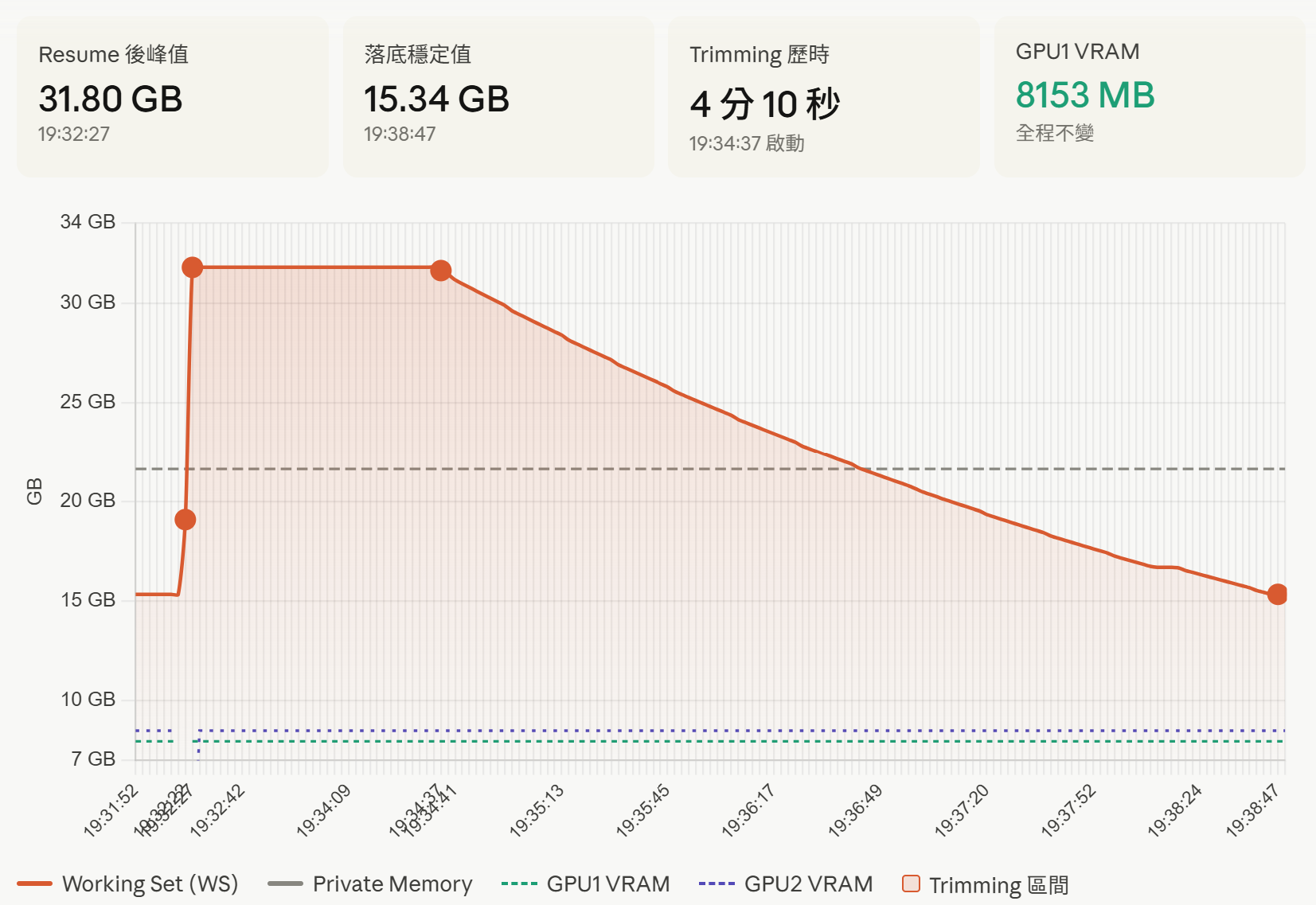
19:31:52 ── 基準線
19:32:22 ── Sleep/Resume 切換瞬間
19:32:27 ── Working Set 峰值
19:32:29~19:32:46 ── GPU 逐步恢復
19:34:37 ── Working Set Trimming 啟動
19:38:47 ── 落底穩定
請在此位置插入圖片 llama_mem_chart.png
圖上有一條細節值得特別注意:灰色虛線(Private Memory)全程平坦在 21.64GB,紋絲不動。Working Set 從 31GB 暴跌,Private Memory 完全沒有反應。
這個對比直接說明了問題的本質:變動的是 Windows 的帳本,不是 llama.cpp 真正持有的記憶體。
為什麼會這樣?三個層次的記憶體
要理解這個現象,需要先把「記憶體」拆成三個不同的概念。
Working Set:Windows 的帳本
工作管理員「處理程序」頁面顯示的記憶體欄位,是 Working Set——目前駐留在實體 RAM、且被 Windows 歸屬給這個程式的頁面總量。關鍵字是「目前」。這個數字是 Windows Memory Manager 在這一刻的決策結果,下一刻可能完全不同。它不是模型的大小,不是 VRAM 的用量,也不是程式「需要」多少記憶體。
Private Memory:程式真正持有的
PrivateMemorySize64 才是 llama-server 真正私有、不能被 Windows 收走的記憶體。這次實測全程 21.64GB,包含 CUDA host buffer、KV cache、runtime 本身。Working Set 怎麼起伏,Private Memory 都不動。
mmap 與 GPU offload 的關係
llama.cpp 載入 GGUF 模型用的是 mmap(),不是直接讀進 RAM。mmap 建立的是「虛擬位址對應磁碟檔案」的映射,實際上哪些頁面在實體 RAM,完全由 Windows 決定。
GPU offload 是把模型權重「複製」到 VRAM,不是「搬走」。所以模型在 GPU1+GPU2 跑著,RAM 裡的 mmap 映射依然存在。Windows 不知道那些頁面已經在 VRAM 了,它只看到一個 16GB 的檔案被 mmap 進來,就把對應頁面算進 Working Set。
| 層次 | 這次數值 | 說明 |
|---|---|---|
| Working Set | 15 → 31.80 → 15 GB | Windows 帳本,動態變化,Sleep/Resume 後暫態膨脹 |
| Private Memory | 21.64 GB(全程不動) | llama.cpp 真正持有,含 CUDA buffer、KV cache、runtime |
| GPU1 VRAM | 8153 MB(全程不動) | 模型主力在此,Windows 完全看不到 |
| GPU2 VRAM | 8701 MB(Resume 後 <2s 恢復) | 模型次要在此,Resume 後短暫 394MB 再跳回 |
Sleep/Resume 為什麼會觸發這個現象
平常沒有 Sleep/Resume 的時候,Windows Memory Manager 早就整理好帳本,mmap 頁面大部分已經被移到 Standby List(File Cache),不算在 Working Set 裡,所以你看到的數字是合理的。
Sleep(S3)喚醒時,Memory Manager 需要重新評估所有程式的 Working Set。它看到 llama-server 有一個巨大的 mmap 映射,保守起見先把能看到的全部算進去,然後再花幾分鐘跑 Working Set Trimming,漸進把不需要的頁面收回 Standby List。
怎麼判斷是真的異常還是帳本暫態
nvidia-smi,VRAM 有沒有掉VRAM 穩定 → 模型仍在 GPU,推論正常
速度正常 → CPU fallback 排除。Qwen3.6 27B 跑回 CPU 會掉到個位數
自動下降 → Windows Working Set Trimming 在進行,正常現象
這才是真正的異常,才需要介入處理
延伸:UMA 架構(Mac Silicon / Strix Halo)能避免這個問題嗎
某種程度上可以。UMA 架構的 RAM 和 VRAM 是同一塊物理記憶體,OS 帳本和 GPU 使用是同一張,不存在「複製到 VRAM 之後 RAM 還留著 mmap 影子」這件事。Sleep/Resume 後的帳本重建問題從架構上就小很多。
| 分離式架構(PC / RTX 3060) | UMA 架構(Apple Silicon / Strix Halo) |
|---|---|
| RAM 和 VRAM 是兩個獨立記憶體池 | RAM 和 VRAM 是同一塊 |
| mmap 在 RAM,offload 複製到 VRAM | 沒有跨池複製,OS 帳本一致 |
| OS 看不到 VRAM,帳本有誤差 | 帳本暫態膨脹問題不存在 |
| Sleep/Resume 觸發帳本重建 | Sleep/Resume 後數字更穩定 |
| VRAM 不夠可退回 RAM 繼續跑(慢) | 模型超過上限就是超過,沒有退路 |
但 UMA 消除的是語意錯位,不是記憶體壓力。模型比統一記憶體大,一樣跑不動。不同的地基,不同的坑。
這次學到什麼
工作管理員的記憶體數字,反映的是 Windows Memory Manager 當下的決策,不是程式真正的資源使用狀況。在 mmap + GPU offload 的架構下,這兩件事可以差很多。
判斷本地 AI 推論是否正常,看 VRAM 和 tok/s,不要看工作管理員的記憶體欄位。後者只適合用來判斷系統整體是否有記憶體壓力,不適合用來判斷模型狀態。
nvidia-smi,看 tok/s,等三分鐘。如果三件事都沒事,那就真的沒事——Windows 只是在重新整理它的帳本。
llama.cpp
Windows Memory
GPU Offload
RTX 3060
Working Set
mmap
CUDA Context
地端AI
工程筆記
Comments