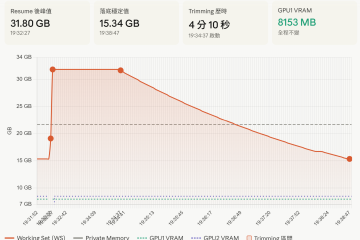
巨頭不是為 SMB 而設計,卻意外改變了 SMB 的 AI 部署門檻
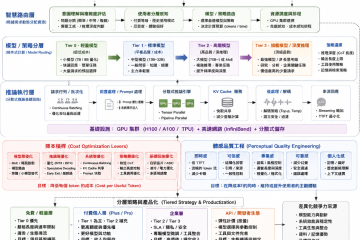
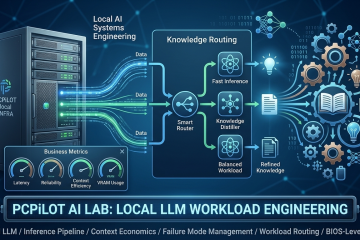
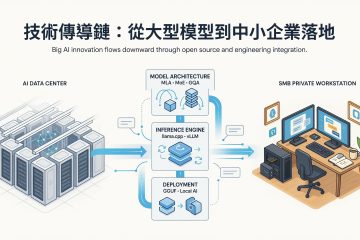
巨頭不是為 SMB 而設計,卻意外改變了 SMB 的 AI 部署門檻 工程師思路系列・事出必有因 | Mr. τ/風雲網通系統 如果把近兩年大型模型(Google、Meta、DeepSeek、阿里、Moonshot 等)的演進整理起來,可以發現一件有趣的事: 幾乎沒有任何一項技術,是專門為 SMB 本地部署而設計。 各家模型公司真正追求的,始終是資料中心的吞吐量(Throughput)、降低雲端服務成本、增加併發(Concurrency),以及降低每百萬 Token 的推論成本。 然而,這些為龐大雲端設施打造的底層技術,透過開源與社群的轉譯,最後卻讓只有雙卡 RTX 3060 12GB、甚至 Mac Studio 的 SMB 使用者,意外成了最大的受益者。 要理解這股紅利如何傳導到地端,不能只看單一名詞,而必須用系統工程的三層架構來拆解。更重要的是,這三層並非平行存在,而是嚴格的依賴與傳導鏈: 模型架構(決定天花板) → 推論框架(決定能不能跑) → 部署技術(決定有沒有資格入場) 例如:MLA 再強,如果推論引擎沒有支援,SMB 一樣享受不到;反過來,GGUF 量化格式再成熟,如果模型本身缺乏 GQA 或高效設計,VRAM 還是會被 KV Cache 瞬間撐爆。唯有三者同步成熟,地端的性價比甜蜜點才會出現。 第一層:模型架構層(決定天花板) 一 MLA(Multi-head Latent Attention)— 以 93.3% 壓縮率突破 KV Cache 瓶頸... » read more