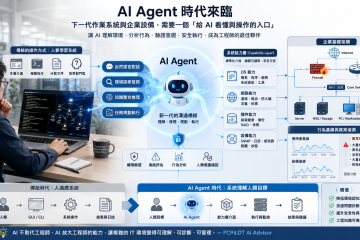
下一代 OS,不只是給人操作,也要讓 AI 理解
下一代 OS,不只是給人操作,也要讓 AI 理解 Mr. τ・風雲網通系統有限公司 二十幾年前,我剛入行的時候,「學會用電腦」這件事本身就是一個專業門檻。不是每個人都知道怎麼開磁碟機、怎麼打 IP、怎麼判讀錯誤代碼。 後來網路普及了,GUI 變得越來越友善,這道牆矮了一半。但對工程師來說,真正的工作仍然是那些 CLI、那些 config、那些藏在第三頁設定選單裡的參數。 現在,AI Agent 出現了。 我不是要說「AI 可以取代工程師」這種老套論述。我想說的是一件更底層的事:人類與複雜系統的互動介面,正在準備迎接第三次重構。 第一次:GUI 讓普通人也能操作機器 過去的作業系統,只有兩層溝通介面: 第一層:GUI 給人用的視覺介面。Windows 設定、NAS DSM、Router 管理介面。你看到的是「按鈕」,不需要知道背後是什麼指令。 第二層:API / CLI 給程式用的系統介面。PowerShell、Shell Script、REST API。工程師的地盤,自動化的入口。 但這兩層都有一個隱藏前提:操作者必須先知道「這個系統有什麼能力」。 你得知道功能在哪裡、工具叫什麼名字、參數怎麼填、錯誤怎麼判讀。這道「認知高牆」從來沒有消失,只是被 GUI 遮住了一部分。 第二次:API 讓程式也能操作機器 REST API 的普及,讓「自動化」成為可能。你不需要真的去點那個按鈕,只要呼叫對的 endpoint、帶對的參數,就能完成任務。 但這層也有門檻:你仍然需要先讀文件,先知道 endpoint 的名稱,先理解資料結構。程式不會「猜」,它只會「照做」。 API 解放了自動化的下限,但沒有解決「讓不熟悉系統的人也能快速上手」的問題。 第三次:AI Capability Layer — 讓 AI Agent 也能理解機器 AI... » read more





![[長篇] PC 平台演化與相容性失效的統一解釋框架 — 契約失效模型 Contract Failure Model (CFM)](https://www.pcpilot.com.tw/wp-content/uploads/2026/07/ChatGPT-Image-2026年7月6日-下午01_00_44-360x240.png)

