
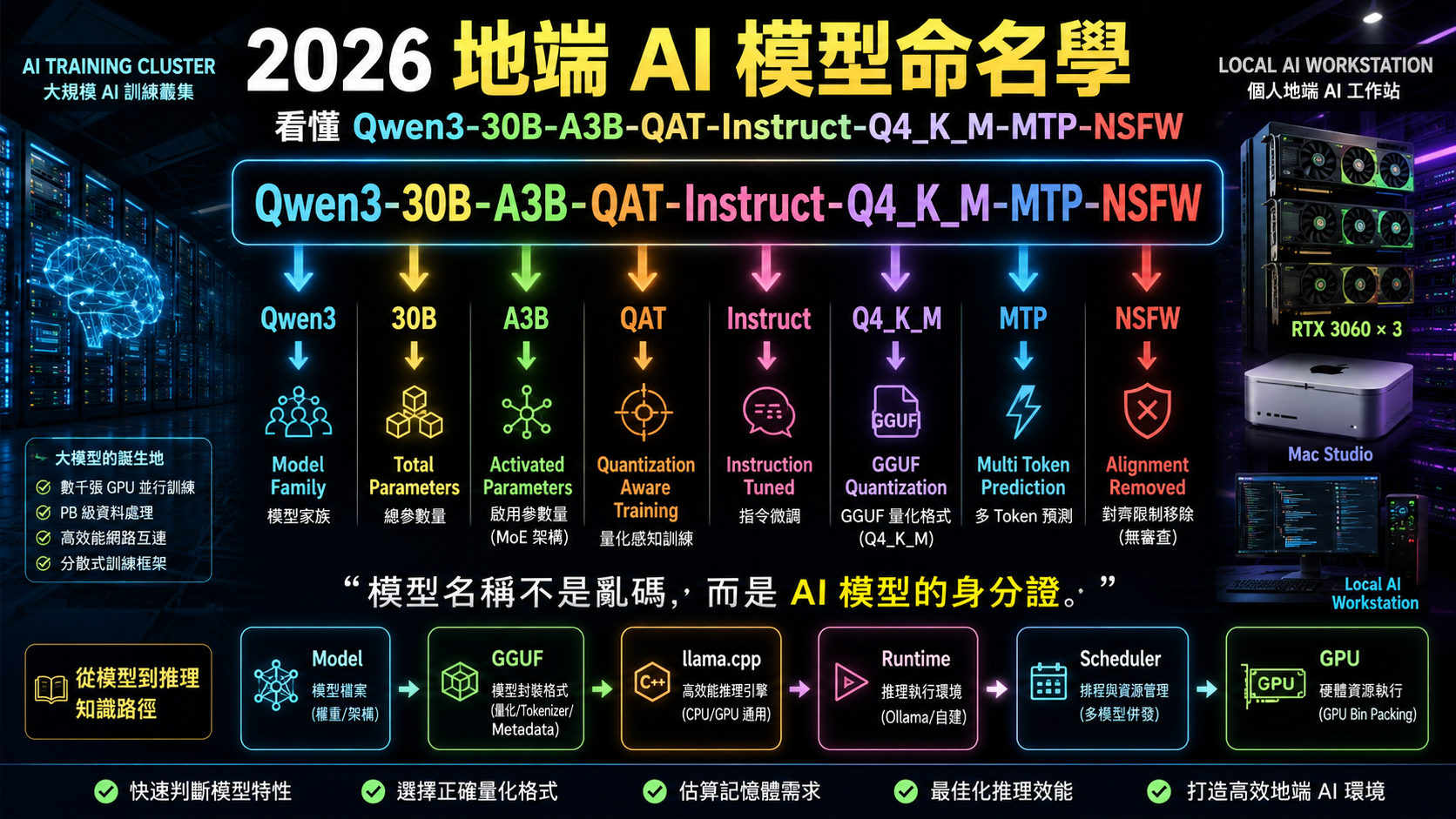
看懂 Qwen3-30B-A3B-QAT-Instruct-Q4_K_M-MTP-NSFW:2026 地端 AI 模型命名學完全指南
從模型名稱看懂參數規模、MoE 架構、量化格式與推理優化
當你開始接觸地端 AI(Local AI)之後,很快就會發現一件事:
最大的障礙不一定是顯示卡,也不一定是 Linux。
而是模型名稱。
第一次看到:
Qwen3-30B-A3B-QAT-Instruct-Q4_K_M-MTP-NSFW
很多人的反應通常都是:
「這到底是模型名稱,還是 Wi-Fi 密碼?」
事實上,這串名稱並不是亂命名。
它其實是在用最短的字數,描述模型的架構、規模、量化方式、推理特性與用途。
如果能看懂這些縮寫,你幾乎可以在下載前就判斷:
- 需要多少記憶體?
- 跑起來快不快?
- 適合聊天還是寫程式?
- 是否支援特殊優化?
- 是否有安全限制?
一、30B 是什麼?
30B 指的是:
30 Billion Parameters
也就是 300 億參數。
參數可以理解成模型在訓練過程中學到的知識權重。
| 模型規模 | 常見用途 |
|---|---|
| 3B | 輕量聊天助手 |
| 7B | 個人 AI 助理 |
| 14B | 進階推理 |
| 30B | 高品質通用模型 |
| 70B+ | 接近大型商業模型能力 |
通常參數越大,能力越強,但所需記憶體也越高。
二、A3B 是什麼?
A3B 是:
Activated 3 Billion Parameters
意思是每個 Token 推理時,大約只會啟用 30 億參數。
這通常出現在近年熱門的 MoE(Mixture of Experts,混合專家)架構。
很多人會誤解:
A3B = 只需要 3B 記憶體
其實並不是。
MoE 模型仍然需要載入完整權重。
只是每次計算時,只會選擇部分 Expert 參與推理。
記憶體需求接近 30B
運算成本接近 3B
三、QAT 又是什麼?
QAT 全名:
Quantization Aware Training
中文通常翻譯為:
量化感知訓練
傳統做法是先訓練出 FP16 模型,再量化成 Q4 或 Q5。
這稱為 PTQ(Post Training Quantization)。
而 QAT 則是在訓練過程中就同步考慮量化誤差。
因此量化後的模型通常能保留較好的品質。
四、Q4_K_M 又是什麼鬼?
如果你使用過 Ollama 或 llama.cpp,
一定看過:
Q4_K_M
Q5_K_M
Q6_K
Q8_0
這些都是 GGUF 生態系的量化格式。
| 名稱 | 含義 |
|---|---|
| Q4 | 4-bit 量化 |
| Q5 | 5-bit 量化 |
| Q6 | 6-bit 量化 |
| Q8 | 8-bit 量化 |
數字越高:
- 品質越好
- 記憶體需求越高
- 速度通常略慢
K 代表 GGUF 的 K-Quant 量化方法。
M 則代表 Medium Variant。
五、GGUF 為什麼會變成主流?
GGUF 可以視為:
地端 AI 世界的 ZIP 檔
它把模型權重、Tokenizer、Metadata 與量化資訊全部封裝在一起。
↓
GGUF
↓
llama.cpp
↓
GPU
因此部署極為方便。
這也是 Ollama、LM Studio、Open WebUI 等工具大量採用 GGUF 的原因。
六、MTP 是什麼?
MTP 代表:
Multi-Token Prediction
多 Token 預測。
傳統模型一次只預測一個 Token。
而 MTP 嘗試一次預測多個 Token。
因此能提升生成速度與 GPU 利用效率。
七、Instruct 呢?
Instruct 表示:
Instruction Tuned
也就是經過指令微調。
如果沒有 Instruct,
模型可能更接近 Base Model,
不一定適合直接聊天。
| 後綴 | 含義 |
|---|---|
| Instruct | 指令微調 |
| Chat | 聊天版本 |
| Code | 程式碼專用 |
| Reasoning | 推理增強 |
| Thinking | 思維鏈強化 |
八、NSFW、Uncensored、Abliterated
最後來談最容易吸引眼球的部分。
當模型名稱出現:
- NSFW
- Uncensored
- Abliterated
通常代表安全對齊(Alignment)被弱化或部分移除。
這類模型限制較少,但也需要使用者自行承擔更多責任。
結語:模型名稱其實是一張規格表
Qwen3-30B-A3B-QAT-Instruct-Q4_K_M-MTP-NSFW
其實是在告訴你:
- 我是 Qwen3 家族模型
- 總共有 300 億參數
- 採用 MoE 架構
- 每次約啟用 30 億參數
- 透過 QAT 訓練
- 適合指令式對話
- 使用 GGUF Q4 量化
- 支援 Multi-Token Prediction
- 安全限制較少
換句話說,這不是一個模型名稱。
而是一張濃縮版的 AI 技術規格書。
當你開始看懂這些縮寫之後,
下載模型不再像抽卡,
而更像是在閱讀 CPU 或顯示卡規格表。
真正的地端 AI 之路,往往就是從看懂第一個模型名稱開始。
Comments