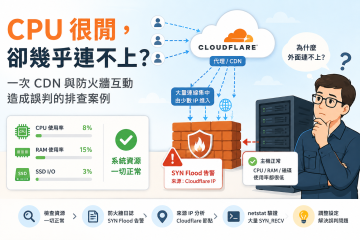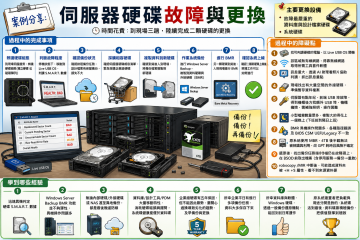
同齡不同命:PDM 伺服器硬碟故障全記錄
工程師思路系列 · 事出必有因 同齡不同命:PDM 伺服器硬碟故障全記錄 兩顆同批硬碟、截然不同的 S.M.A.R.T. 數據,說明了一件事—— 客戶的 PDM 主機頻繁出現 BSOD,三趟現場、兩顆硬碟更換、一次與故障碟搶時間的緊急救援——這篇文章完整記錄過程與教訓,以及這個案例如何成為我們開發硬碟分析工具的直接動機。 伺服器硬碟配置 磁碟 型號 用途 最終狀態 Disk 1 Seagate Exos E7B 2TB C:(Windows Server 2016)+ E:(備份區) 健康,無明顯瑕疵磁區 Disk 2 Seagate Exos E7B 2TB Oracle 資料庫 + PTC Windchill / Creo 設計檔案 瑕疵磁區數以萬計,已嚴重劣化 兩顆硬碟同型號、同時間採購上線,帳面上應該「狀況差不多」。實際展開 S.M.A.R.T. 數據後,結果令人震驚——兩顆同齡的硬碟,健康落差大到像是相差了好幾個世代。 「同齡不同命」——Workload Rate Limit 沒說的那件事 廠商的 Workload Rate Limit(年工作量上限)衡量的是「搬運了多少資料」,而不是「磁頭來回了幾次」。 Disk... » read more

![[長篇] PC 平台演化與相容性失效的統一解釋框架 — 契約失效模型 Contract Failure Model (CFM)](https://www.pcpilot.com.tw/wp-content/uploads/2026/07/ChatGPT-Image-2026年7月6日-下午01_00_44-360x240.png)