

前言:效能與品質的拔河
在追求地端大型語言模型(LLM)的過程中,許多企業主與開發者常面臨一個抉擇:在現有的硬體資源(如單片 24GB 顯存環境)下,究竟該追求模型參數的大小,還是追求輸出的穩定性?
最近我在實際操作 PCPiLOT 的核心邏輯時,對 26B / 27B 等級模型進行了深度測試,發現了一個極為現實的技術瓶頸。這篇文章將解析為什麼「模型塞得進去」不代表「真的好用」。
一、 模型變大,不代表生產力提升
以 26B / 27B 等級的模型(如 Qwen 或 Gemma 系列)來說,輸出的邏輯與表達確實非常出色,甚至接近商用等級。
但問題在於:在 24GB VRAM 的環境下,這類模型幾乎把資源吃到極限。這就像一台超載的貨車,雖然還能上路,但已經沒有任何避震空間與加速餘裕。
二、 隱形的效能殺手:KV Cache 與上下文長度
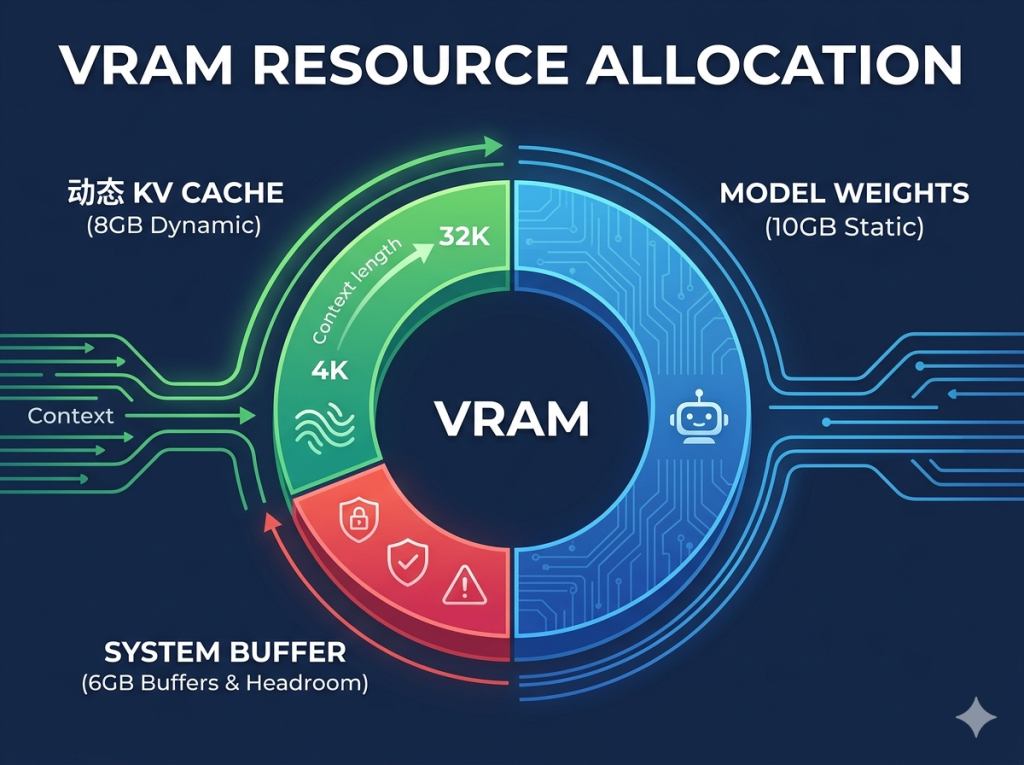
許多人評估硬體時,只看「模型權重大小」,卻忽略了推論過程中的動態變數:
- KV Cache(注意力快取): 這是模型處理對話內容時的暫存空間。
- 上下文長度(Context Length): 當你對話輪次增加(例如拉到 32K 或更高)時,KV Cache 會像吹氣球一樣迅速膨脹。
當 VRAM 被模型權重與 KV Cache 噴滿後,系統會被迫將資料外溢到電腦記憶體(RAM)。此時,推論速度會出現「斷崖式下降」,從流暢的每秒十幾字,變成讓人難以忍受的一秒一字。
三、 實戰取捨:為何我目前改採 9B 模型?
為了確保 PCPiLOT 知識中心的運作效率,我目前的工程策略是改用 Qwen 3.5 9B 先撐住。這並非退步,而是基於「可用性」的權衡:
- 穩定性: 避免顯存溢出導致的推論崩盤。
- 低延遲: 保持互動的流暢感,這在開發環境中至關重要。
- 長上下文支持: 留出更多空間給 RAG(檢索增強生成)使用。
這是一個典型的工程觀念:不追求極致的靜態品質,而是追求「可用性 + 穩定性」的綜合表現。
四、 給地端部署者的三條建議
- 重新定義甜蜜點: 對於 24GB 顯存的使用者,7B 到 13B 級別的模型(尤其是優質的 9B 模型)往往是性價比最高的選擇。
- 預留呼吸空間: 部署時務必預留 4GB 到 8GB 的 VRAM 給 KV Cache,否則長對話絕對會撞牆。
- 從「能跑」到「順跑」: 地端 AI 的瓶頸已經不是能不能跑起來,而是能不能在合理速度下持續運作。
五、 結語:專業顧問的價值
身為從 2005 年就開始深耕資料基礎設施的系統整合商,我認為真正的技術專家不是推薦最強的模型,而是能幫客戶在有限的資源中,找出最穩定、最有效率的架構方案。
如果您對企業地端 AI 部署、NAS 方案整合有更多需求,歡迎關注 PCPiLOT 知識中心,我們持續為中小企業提供精確的 IT 決策建議。
作者簡介
Steven Lai PCPiLOT 創辦人 / 資深 IT 系統整合顧問 20 年資料基礎設施經驗,專注於 SMB 企業 AI 落地與 CKO 知識委外方案。
Comments